Why vector embeddings are here to stay


Every few weeks, a new GenAI model arrives—smarter, faster, cheaper, and poised to outshine the rest. The claims stay the same, even as the names change. In just the past few weeks alone, we’ve seen:
- DeepSeek’s new AI is smarter, faster, cheaper, and a real rival to OpenAI's models
- Why Anthropic's latest Claude model could be the new AI to beat
- Google says its new ‘reasoning’ Gemini AI models are the best ones yet
If you pay attention to research studies, breaking press releases, and new funding rounds, the pace of the news gets even faster. It can feel impossible to keep up with.
As Vicky Boykis, former senior machine learning engineer at Mozilla.ai, writes, “There's a whole universe of exciting developments at the forefront of large language models. But in the noise of the bleeding edge, a lot of important foundational concepts get lost.”
Innovation is like rock climbing. Some advancements are like footholds—useful, but you push off from them and don’t look back—and some are like ropes—continuously useful the more you pull on them. Sometimes, the longest-running ideas are the ones that will continue to push us forward.
Without understanding these foundational concepts, Boykis writes, “The models will remain black boxes to us. We won't be able to build on them and master them in the ways that we want.”
If you want to build on GenAI models, then learning about embeddings is one of the best places to start. Even though embeddings have been around for decades, there’s still much more potential to be realized from the core idea they represent. If anything, their persistence over the years proves their staying power.
For engineering leaders, allowing models to remain black boxes is not an option. Keeping up and staying ahead of GenAI requires a deep understanding of embeddings. But the best engineering leaders won’t stop there. Forward-thinking engineering leaders will look for opportunities to extend the power of embeddings through technologies like RAG and opportunities to support embeddings through technologies like vector search.
A brief history of embeddings
Embeddings transform text, images, and audio into vectors that machine learning (ML) models use to parse and process complex data.. Think of embeddings as the common language that ML models speak. Each data format is like a different way of speaking, but embeddings enable conversation among them all.
This idea of a common language, of representing data by its relationships to other data, traces back to the 1950s. John Rupert Firth, an English linguist, wrote in a 1962 paper, “You shall know a word by the company it keeps!” There was meaning, linguists thought, not just in words themselves but in the context you found them in.
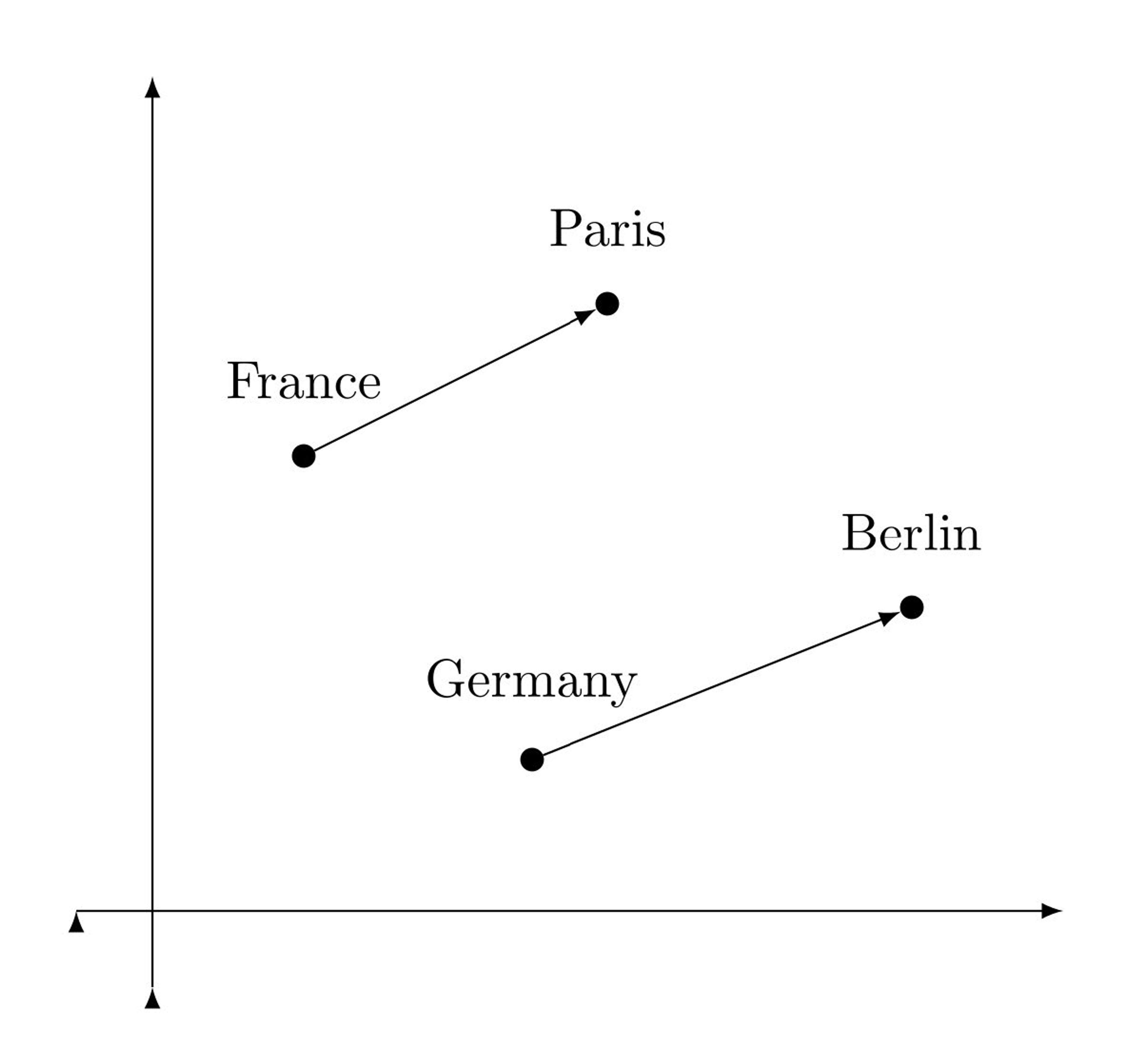
(Source)
It took decades for this idea to evolve and take on mathematical significance. The concept of representing meaning in a mathematical space has its roots in distributional semantics, which can be traced back to research conducted in the 1990s. In those days, embedding methods were limited, however, because representations were sparse.
In 2013, Google researchers introduced Word2Vec, a toolkit that made it possible for ML models to learn dense vector representations of words from large datasets. Word2Vec was a huge milestone in embeddings, and in NLP more broadly, because it showed that learned embeddings could encode relationships.
The image below, for example, uses color encodings to illustrate and compare the relationships between words and the different levels of similarity between them. “Man” and “woman,” for example, are more similar to each other than either is to “king” or “queen.”
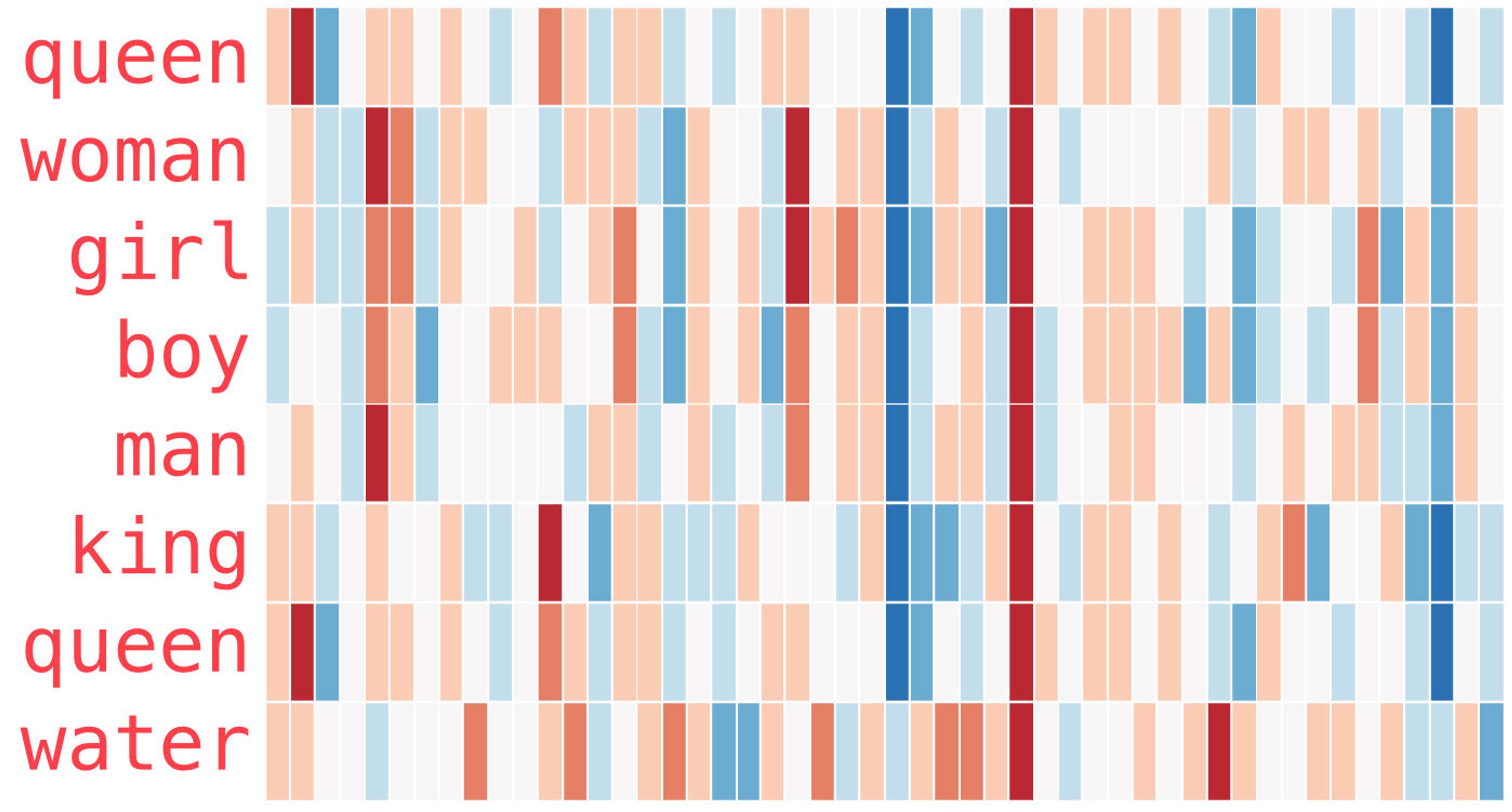
(Source)
In 2017, researchers introduced transformer architecture via the paper “Attention Is All You Need,” which showed developers how to build models that attended to every word in a sentence.
Soon after, in 2018, Google released BERT (Bidirectional Encoder Representations from Transformers), an open-source framework that displayed the power of this new approach by offering rich, contextual word embeddings. Unlike Word2Vec and other models, BERT was able to consider the entire sentence, even though the same word had different vectors in different sentences.
The introduction of transformers marked a watershed moment; even years later, models like GPT owe their fundamental advancements to transformer architectures.
Understanding embeddings can feel “elusive,” Boykis writes. “They’re neither data flow inputs or output results—they are intermediate elements that live within machine learning services to refine models.”
To understand embeddings—even at a high level—it helps to go back to the core idea of how meaning is represented.: When you say the word “home,” you’re representing a lot of potential meanings using a sound made by your body. The word “home” compresses all those meanings into a sound that you can transfer from person to person. Embeddings do the same, but for many different data formats, and do so not for person-to-person communication but for training and supporting ML models.
The role of embeddings in AI
Some ideas are foundational, and some extend the leading edge of what’s possible before being traded in for the next advancement. Embeddings are a rare idea that does both: They precede GenAI by decades, but advancements in AI often come from using embeddings in new and interesting ways.
Nuance
Embeddings can enhance accuracy and generalization by allowing an algorithm to recognize similarities between concepts without being explicitly instructed to do so. “Happy,” for example, is closer to “joyful” than to “cat,” and embeddings make it possible for algorithms to recognize that relationship.
As a result, in a wide range of natural language processing (NLP) tasks, including classification and machine translation, embeddings are essential. They allow for the algorithms to consider semantic similarity between words, rather than just exact matches. Without them, “cat” and “kitten” would appear like entirely dissimilar words just because the letters are different.
Transferability
Embeddings can be trained on a single task or domain and then reused or fine-tuned for another domain. The learned semantic structure is transferable across contexts, which is a foundational element of GenAI’s ongoing growth.
Without transferability, GenAI apps would be isolated and siloed; with transferability, they can improve and become more comprehensive over time.
Efficiency
High-dimensional data is often noisy, complex, and difficult to parse. Embeddings reduce dimensionality while preserving the relationships between data points, accelerating model training times and decreasing computational costs.
NLP & LLMs
Almost all modern NLP models, including large language models (LLMs) like GPT, rely on embeddings. These models convert words, sentences, documents, and other content into vectors that encode meaning—representations the model uses to interpret input and generate output. Embeddings aren’t just an implementation detail; they’re how large language models understand and represent everything they encounter. They’re the entry point to reasoning. This supports functionalities like semantic search, question answering, and transfer learning.
Recommender systems
Most recommender and personalization systems rely on embeddings. In this context, embeddings typically represent users and items in the same vector space, allowing, for example, a movie recommender system to derive patterns of user behavior that correlate with particular item attributes.
Take Netflix for example. The company built a foundation model for personalized learning that uses embeddings throughout. The diagram below illustrates how each type of metadata associated with a show or movie can be represented by its corresponding embeddings.
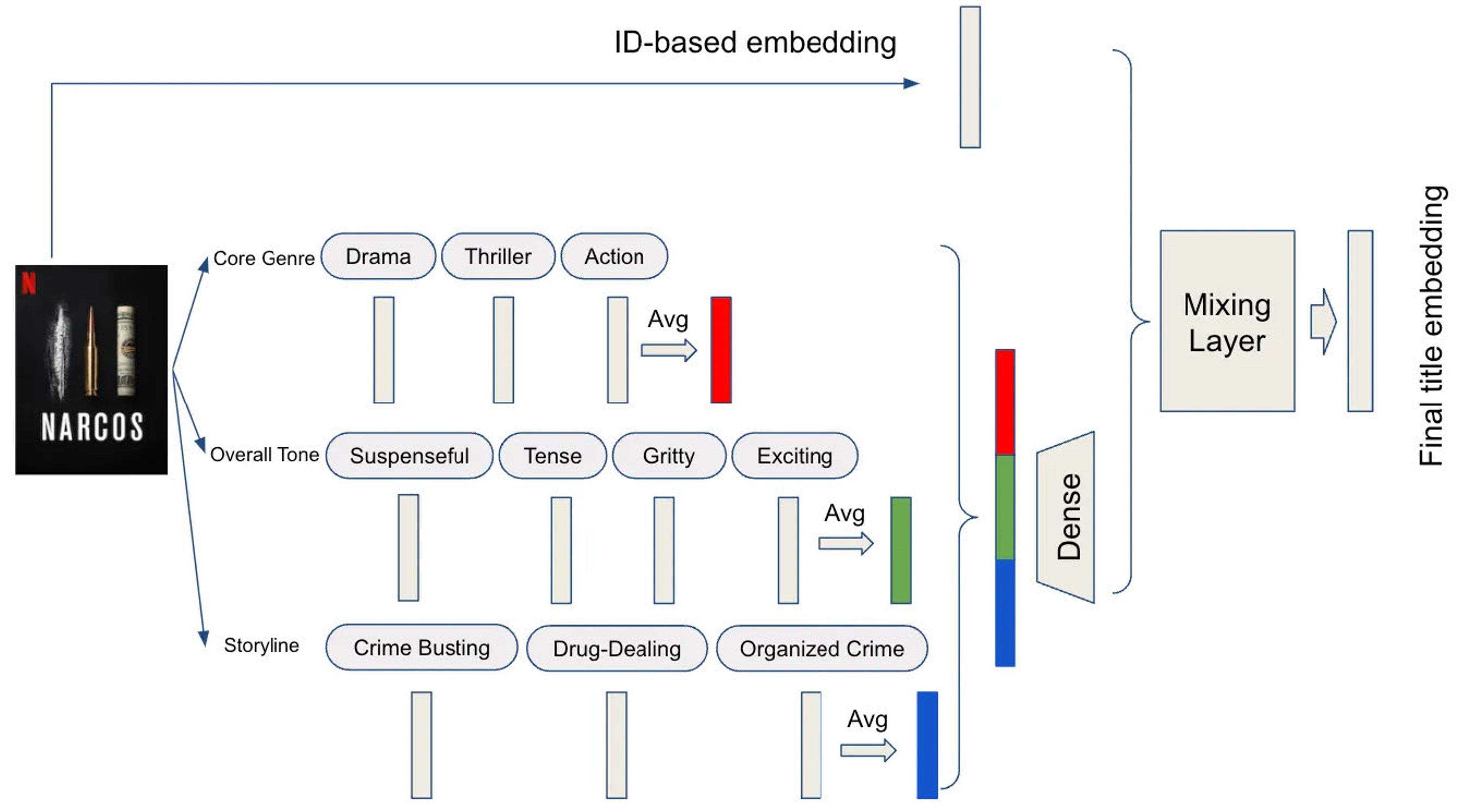
(Source)
Google Play, Overstock, Airbnb, and many other companies use embeddings in recommender systems for similar purposes.
The bright future of embeddings
Embeddings have proven to have a lasting role in AI, and the development of embeddings has also led to a long tail of advancements in other use cases. As GenAI evolves, you’ll see embeddings in everything GenAI touches, and as the usage of embeddings spreads with the adoption of GenAI, the role of vector storage and search will only become more central.
Multimodal embeddings will continue to unlock new knowledge sources
Multimodal embeddings allow ML models to encode images, audio, and other data in the same vector space, allowing models to reason across modalities. Multimodal embeddings can connect the word "cat," an image of a cat, and the sound of meowing together. As a result, search features can work across a wide range of formats.
For example, with Google's Multimodal Embeddings API, you can, as shown in the image below, search for the text “cat” or a picture of a cat.

Embeddings have long been able to incorporate multimodal sources, but advancements in this area hold considerable promise.
LLMs are more intelligent than the sum of their parts: Every new piece of information isn’t just an additional idea to consider, but is a new node in a network that gets exponentially more intelligent as it connects ideas.
Training an LLM on a new book, for example, is a good addition, but unlocking an entire corpus of information by making video recordings parsable is a much bigger addition.
RAG is growing, bringing embeddings with it
RAG, or retrieval-augmented generation, is a search technique that enhances the accuracy of a GenAI model by integrating and prioritizing trusted knowledge sources. A RAG app retrieves information from a trusted source using vector search, which relies on embeddings, and presents it as context to the LLM before the LLM generates a response.
Embeddings support the efficient retrieval of relevant documents in large databases, cluster similar texts to identify trends and topics, automatically categorize text, and identify duplicate content, making RAG much more practical.
In March of 2025, for example, Google touted advancements in text embedding to support, among many use cases, RAG.
Embeddings already play a significant role in RAG, so their importance will likely increase as RAG becomes more widely adopted. Menlo Ventures research shows that in 2024, embeddings became the most popular enterprise AI design pattern.
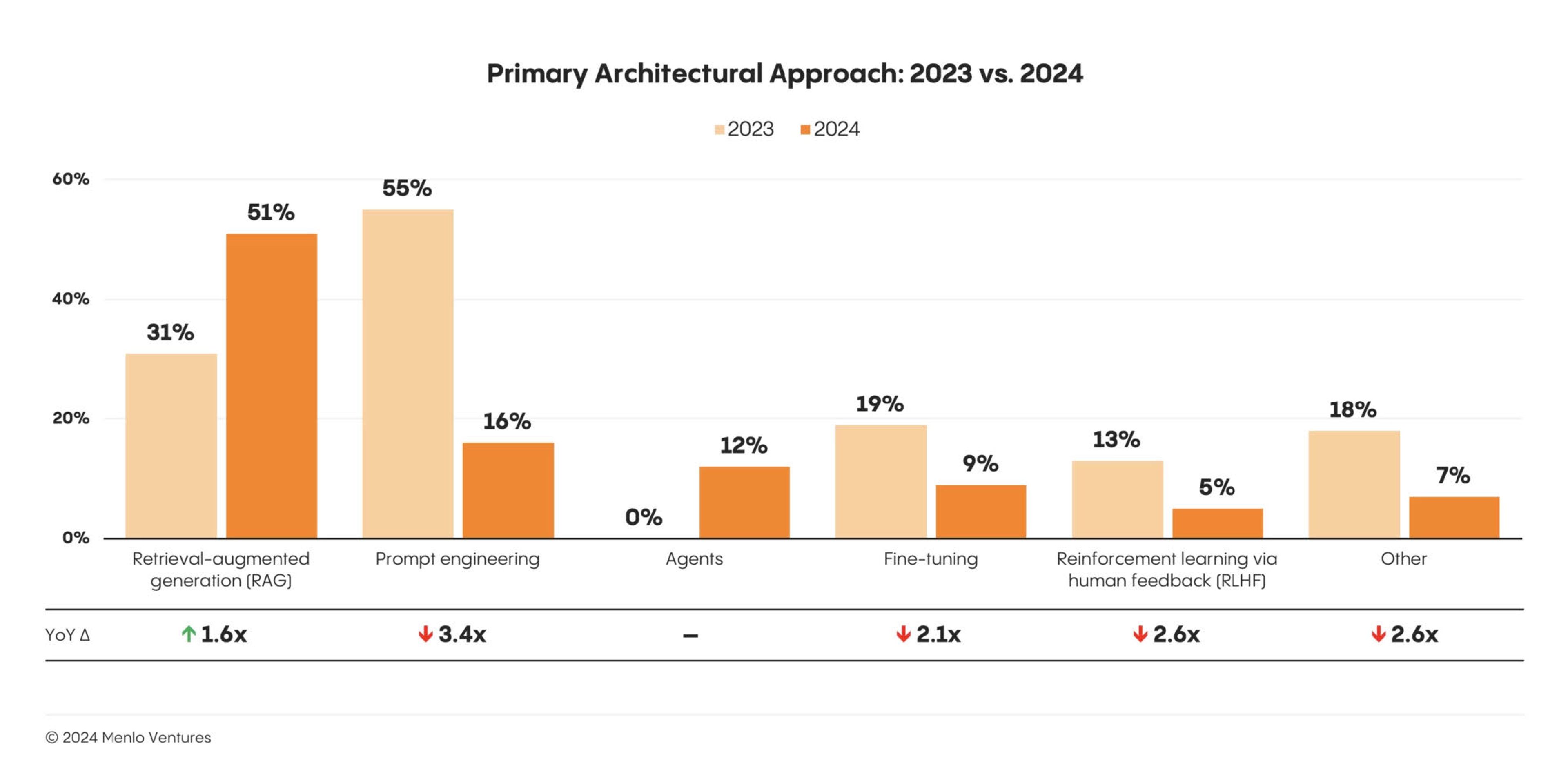
For enterprise use cases, where accuracy is a priority and alignment with internal knowledge is paramount, RAG promises to be one of the most impactful approaches to GenAI, making embeddings a core technique for all enterprise engineering leaders to learn.
Vector databases & search will keep growing
As a result of the growth, spread, and advancement of embeddings, technologies that support and enhance them will continue to grow in importance. Among those technologies, none are better positioned for growth than vector databases and vector search.
Because embeddings compress information into vectors, the growing use of embeddings-based approaches keeps vector databases and vector search at the center of GenAI adoption and maturity. This is where Redis stands apart—not just as a fast database, but as a real-time one, which is critical for delivering low-latency, high-throughput performance GenAI apps demand.
The key point is that companies can’t rely on a “good enough” approach to vector storage; improving your approach to vector utilization can create a step change in your usage of GenAI more broadly.
Redis delivers vector storage and search with standout performance, including high throughput, low latency, and full support for use cases like RAG. It also integrates seamlessly with a wide range of AI and data tools. Our research, based on objective benchmarking, proves that Redis is, by far, the fastest option on competitive vector metrics.
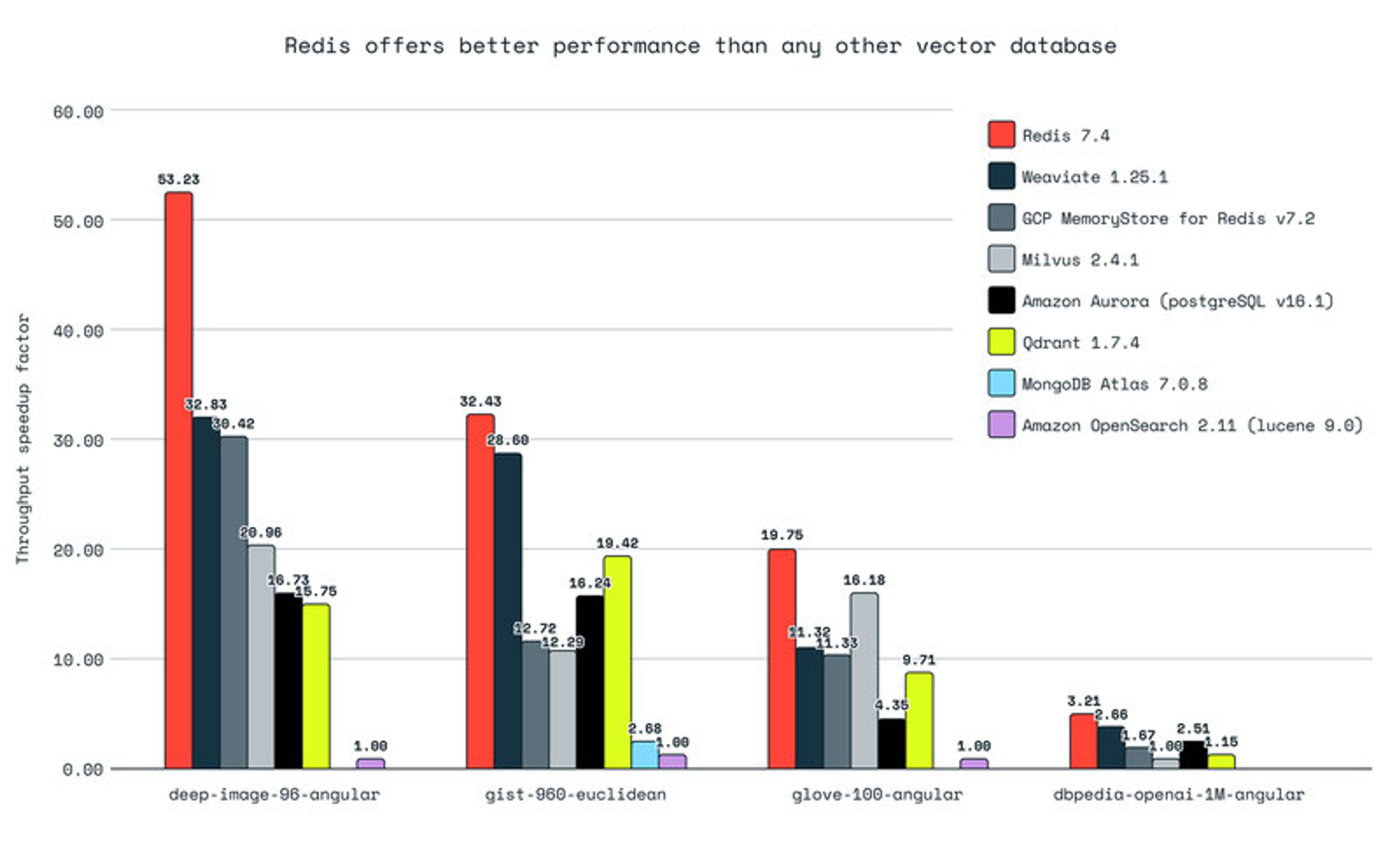
Harrison Chase, Co-Founder and CEO of LangChain, says, “We’re using Redis Cloud for everything persistent in OpenGPTs, including as a vector store for retrieval and a database to store messages and agent configurations. The fact that you can do all of those in one database from Redis is really appealing.”
When you look at a paradigm shift like GenAI, you have to look beyond the most obvious technologies. Like a rising tide lifting all boats, the rise of GenAI will also mean the rise of embeddings, vector search, and vector storage. As an engineering leader, your job is to ensure that your approach to each of these technologies reaches a high watermark.
Embeddings make finding information easier
Information is vast, complex, and chaotic. Every advancement in condensing and taming that chaos, whether that be the printing press or ChatGPT, has triggered massive advancements in human knowledge.
Embeddings, at their core, make it easier to find information. As a result, embeddings are here to stay, and remain a rare anchor in the storm of breaking news surrounding GenAI. Redis is supporting this new ecosystem with a high-performance vector database that supports vector embeddings today, and what comes next. For engineering leaders, understanding embeddings and adopting technologies that support them is one of the best ways to build the foundation for GenAI now and well into the future.